
Monad : la blockchain à très haut débit

Nous vous avons présenté Monad, la nouvelle blockchain de couche primaire (Layer 1) aux performances exceptionnelles. Son haut débit de transactions (10000 par seconde) repose sur différentes briques techniques. Nous avions tout d’abord détaillé le fonctionnement de son algorithme de consensus, MonadBFT. Aujourd’hui, nous allons nous attarder sur sa couche d’exécution, qui permet de paralléliser les tâches.
Monad et la parallélisation de l’exécution des transactions
Sur Ethereum, la couche de consensus et celle de l’exécution sont confondues. Sur Monad, ces couches sont découplées, ce qui permet d’atteindre un haut débit de transactions. La couche d’exécution permet ainsi de traiter les transactions du réseau en parallèle, et non unes à unes. Cependant, la structure des blocs reste la même : l’ensemble des transactions est ordonnancé de façon linéaire.
Le procédé de parallélisation employé sur Monad est appelé optimistic execution – exécution optimiste. On utilise l’adjectif « optimiste » car les transactions sont exécutées avant que d’éventuelles transactions afférentes, la précédent au sein du bloc, ne l’aient été.
Pour reprendre l’image de l’équipe de développement de Monad, ce procédé de pipelining peut être vu comme un lave-linge. Paralléliser l’exécution des transactions revient à les découper en plus petites tâches, pouvant être lancées simultanément. Plutôt que laver, sécher, plier et ranger la première lessive avant de commencer la seconde, il s’agit de lancer la deuxième lessive lorsque la première est mise dans le sèche-linge.
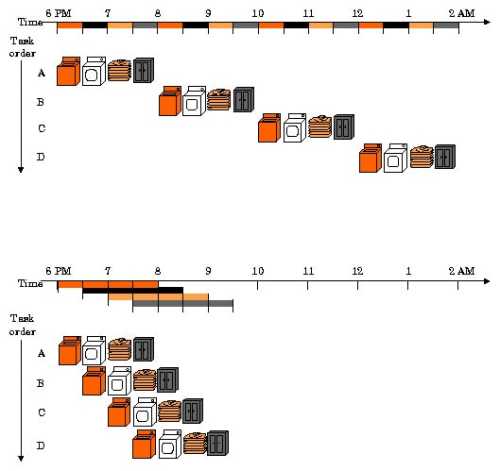
L’exécution parallèle sur Monad illustrée.
Optimist execution
Si les transactions sont traitées en parallèle, sans attendre le résultat d’exécution des transactions précédentes, cela peut mener à des résultats incorrects.
Par exemple, une première transaction peut transférer des coins d’un compte A à un compte B, tandis qu’une deuxième transfère des coins du compte A au compte C. Les deux transactions vont tout d’abord lire puis mettre à jour le solde du compte A. Si la deuxième transaction est exécutée avant la première, cela peut amener à une erreur, quant à la lecture du solde du compte A pour la première. Ce cas de figure ne peut pas arriver dans le cadre d’une exécution parfaitement séquentielle.
Il faut donc trouver des méthodes pour corriger ces erreurs, dans le cadre de l’exécution optimiste. En science informatique, on parle d’accès concurrent. Il faut s’assurer que les résultats d’opérations concurrentes sont générés en un minimum de temps. Sur Monad, les transactions sont exécutées simultanément, tout en mettant à jour et en fusionnant les états relatifs à chaque transaction, de façon séquentielle, pour s’assurer que le résultat est correct.
Implémentation
Les transactions qui doivent être réexécutées ne sont détectées qu’une fois que les transactions précédentes du bloc ont été exécutées. Puisque les états des transactions ont été fusionnés, il est impossible que la transaction échoue une deuxième fois.
Les tâches qui ne dépendent pas de l’état résultant des transactions – comme la récupération des signatures, qui est coûteuse en calcul – n’ont pas à être exécutées à nouveau. De plus, de façon générale, les comptes et les données concernées sont toujours en mémoire cache, ce qui évite également de refaire des opérations coûteuses.
Planification
Monad détermine préalablement les dépendances entre les transactions. En effet, l’exécution optimiste en version « naïve » consisterait à exécuter les transactions en fonction des ressources processeur disponibles. Dans le cas d’un bloc contenant de longs enchaînements de transactions dépendant les unes des autres, l’exécution optimiste génèrerait de nombreuses erreurs.
Monad comporte donc un analyseur de code statique, qui permet de prédire les dépendances dans la plupart des cas. Les transactions sont alors planifiées pour être exécutées une fois que les transactions pré-requises ont été effectuées. Dans les rares cas où cela échoue, Monad a recours à l’implémentation naïve.

MonadDB
MonadDB est la base de données servant à stocker l’état du système. Pour rappel, l’état d’une blockchain est constitué de toutes les données du système : solde des différents comptes, code des contrats, etc.
Les structures de données sur Ethereum
Sur Ethereum, la plupart des logiciels client utilisent un système de clé-valeur. Les données sont structurées sous forme d’arbre (B-tree ou Log Structured Merged Tree) en utilisant par exemple :
- Lightning Memory-Mapped Database (LMDB) ;
- LevelDB ;
- RocksDB.
Cependant, Ethereum lui-même utilise les arbres de Merkle. Plus précisément, la structure de données s’appelle Patricia-Merkle Trie pour Practical Algorithm To Retrieve Information Coded in Alphanumeric. Elle permet de récupérer efficacement des items au sein de l’ensemble des données composant l’état d’Ethereum – retrieval. Cependant, dans le cas de Monad, intégrer une structure de données au sein d’une autre serait suboptimal.
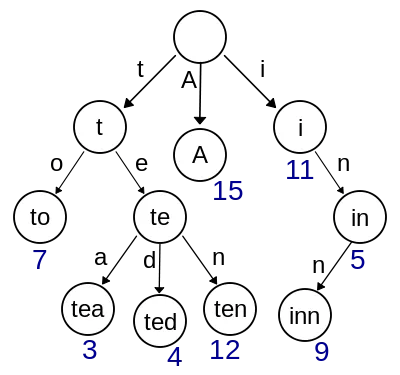
Exemple de Patricia Trie – L’arbre utilise une clé comme chemin, afin que les nœuds qui partagent le même préfixe puissent également partager le même chemin. Le système asynchrone de Monad
Monad exécute les transactions en parallèle. Cela signifie donc que lorsqu’une transaction doit accéder à l’état du système, stocké sur le disque dur, il ne faut pas à avoir à attendre que l’opération se termine. L’opération de lecture doit être initiée, puis le système doit passer à la suivante dans le même temps.
Monad structure les données en Patricia-Trie de façon native, à la fois en mémoire et sur le disque. Le système permet d’accéder en entrée et en sortie de façon asynchrone à la base de données – asynchronous I/O. MonadDB permet donc au processeur de continuer l’exécution de ses opérations, tandis qu’il continue de communiquer avec le disque.
De plus, les disques SSD permettent aussi de paralléliser les opérations, ce qui permet au processeur d’initier plusieurs requêtes simultanément. Il continue alors ses opérations, et reçoit plusieurs résultats au même moment.
En utilisant les dernières API pour l’async i/o (io_uring sur Linux), MonadDB évite d’utiliser un trop grand nombre de tâches CPU pour s’occuper des requêtes. Cela permet d’optimiser ce travail d’entrée/sortie disque asynchrone. Il y a d’autres domaines d’optimisation : par exemple, MonadDB n’a pas recours au système de fichiers, ce qui allège le processus.
Cycle de vie d’une transaction Monad
Avec ces points-clé en tête, ainsi que ceux qui ont été évoqués dans l’article sur le mécanisme de consensus MonadBFT, nous pouvons reconstituer le cycle de vie d’une transaction. Monad est EVM-compatible et utilise aussi un système de compte.
Initiation de la transaction
L’utilisateur initie une transaction en la signant et en la soumettant à un nœud RPC grâce à son wallet. Le gas nécessaire est estimé par le logiciel par défaut (bien que l’utilisateur puisse définir la limite lui-même). Le prix du gas est fixé par l’utilisateur – en jeton natifs par unité de gas. Pour rappel, les frais de transactions sont constitués :
- Du coût d’exécution ;
- Du coût de transport, nécessaire pour éviter le spam de la blockchain.
Chaque compte Monad dispose de deux soldes afférents à ces deux types de frais de gas (solde de réserve et solde d’exécution).
Propagation dans le mempool
Le nœud RPC va ensuite propager la transaction aux autres nœuds Monad qui participent au consensus. Pour rappel, le mempool est partagé, c’est-à-dire que les nœuds n’ont pas tous le même ensemble de transactions. Les nœuds s’assurent préalablement que le gas présent dans le solde de réserve du compte utilisateur concerné est suffisant.
Inclusion dans le bloc
Le leader et producteur du bloc inclus la transaction et ôte du solde de réserve du compte son coût de transport. Le bloc est ensuite propagé selon la méthode de MonadBFT. Une fois qu’il a reçu son certificat de quorum (rappel : à la majorité des ⅔) il est finalisé.
Une fois le bloc finalisé, la transaction est officiellement incluse dans l’historique de la blockchain. Les valeurs et l’état du système sont déterminés immédiatement après exécution.
Exécution locale
Chaque nœud qui finalise un bloc commence immédiatement à exécuter les transactions correspondantes en parallèle : exécution optimiste. Cependant, c’est comme si elles étaient exécutées en série, puisque les résultats sont déjà ordonnancés.
Les utilisateurs peuvent utiliser tout nœud RPC pour requêter le résultat de leur transaction, via eth_getTransactionByHash ou eth_getTransactionReceipt. Le nœud enverra la réponse dès que l’exécution sera complète en local.

Monad en pratique
Afin d’installer un nœud Monad, il faut disposer du matériel suivant :
- Processeur 16 cœurs ;
- 32 Go de RAM ;
- 2 To en SSD ;
- 100 Mbits/s de bande passante.
Pour ceux qui seraient intéressés par le développement sur Monad, et qui ont déjà une bonne expérience avec Ethereum, rien de plus simple. Monad est pleinement compatible avec l’EVM et supporte tous les codes opératifs et les précompilés du fork Shanghai.
Les environnements de développement en Solidity classiques d’Ethereum, comme Remix, sont recommandés. Il en va de même pour les librairies du type OpenZeppelin et les diverses boîtes à outils.
Avant l’arrivée du testnet de Monad, prévu pour les prochains mois, il est donc possible d’utiliser ceux d’Ethereum.
Conclusion et ressources
Monad promet d’être le prochain layer 1 à faire parler de lui. Prévu pour être deux fois plus performant que Solana en termes de débit, et pleinement EVM-compatible, nul doute que vous en entendrez à nouveau parler dans nos colonnes. En attendant, n’hésitez pas à consulter les ressources suivantes :
Nos articles dédiés :
- Le projet de layer 1 Monad réussit à lever 255 millions de dollars
- Monad : la blockchain qui parallélise l’EVM pour atteindre les 10 000 tx/s
- MonadBFT : un algorithme de consensus super-scalable
- Monad : pourquoi un layer 1 plutôt qu’un rollup ?
Ressources officielles :
- Site web
- Documentation
- Discord
- Telegram
Source: journalducoin.com


