

D’ici mi-2025, environ 35 % des nouveaux sites web seront créés en tout ou en partie grâce à l’intelligence artificielle, selon des chercheurs de l’université de Stanford.
Avant le lancement public de ChatGPT d'OpenAI en novembre 2022, ce chiffre était quasi nul. En quelques années, la part des contenus basés sur l'IA a dépassé le tiers des nouvelles publications sur Internet.
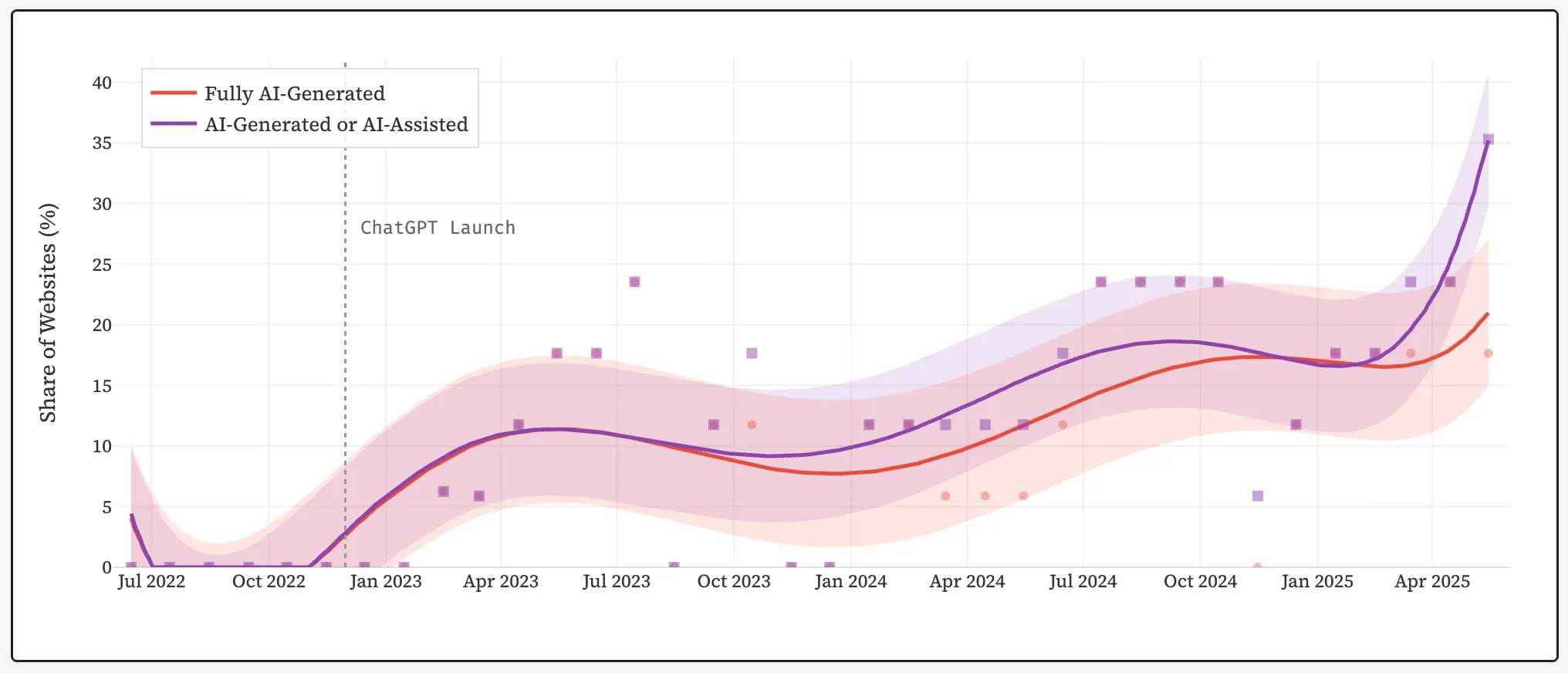
Part des sites web générés entièrement par l'IA (rouge) et également créés à l'aide de réseaux neuronaux (violet). Source : GitHub.
Des chercheurs ont analysé 33 mois d'archives de sites web provenant de la Wayback Machine à l'aide du détecteur Pangram v3. L'objectif est de déterminer comment le développement des textes générés par l'IA restructure le Web.
Changements clés
On observe une diminution de la diversité sémantique. Les pages générées par les réseaux neuronaux sont 33 % plus similaires entre elles que les textes rédigés par des humains. Différents sites web reprennent de plus en plus les mêmes idées dans des formulations quasi identiques.
D'après les auteurs, il ne s'agit pas seulement de rédaction publicitaire de masse à l'aide de l'IA. Le problème est plus profond : la variété des formulations et des idées se réduit progressivement. Les grands modèles de langage (GML), par nature, sélectionnent les réponses les plus « moyennes » et reproduisent un discours stéréotypé.
Le ton émotionnel des publications a également changé. Le contenu généré par l'IA était 107 % plus positif que celui généré par des humains. Stanford a attribué ce phénomène à la tendance, déjà documentée, des titulaires d'un LLM à flatter.
Lors de la phase d'apprentissage, les développeurs optimisent les réseaux neuronaux pour produire des réponses agréables, sûres et socialement acceptables. De ce fait, une part importante des nouveaux sites web crée un environnement informationnel « d'une convivialité aseptisée ». On y observe moins de jugements sévères et de conflits, mais aussi moins de débats passionnés.
Ce qui n'a pas été confirmé
Plusieurs craintes répandues n'ont pas été confirmées statistiquement. Les chercheurs n'ont trouvé aucune corrélation significative entre l'augmentation de la part du contenu généré par l'IA et une baisse de la précision réelle, une augmentation du nombre d'erreurs manifestes ou un alignement stylistique complet des textes sur un modèle unique.
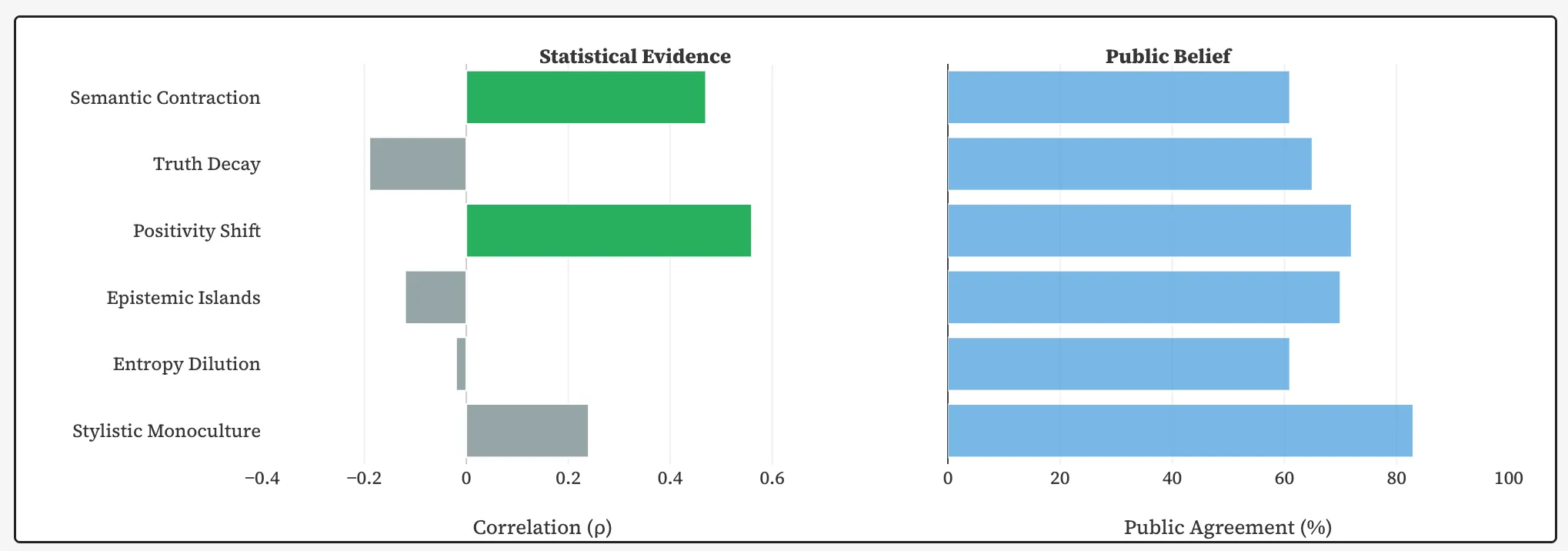
À gauche : Corrélation entre le contenu relatif à l’IA et les hypothèses. À droite : Proportion d’adultes américains qui approuvent chaque hypothèse. Source : GitHub.
Des scientifiques ont par ailleurs mis en évidence un effet qui a jusqu'à présent été principalement abordé sur le plan théorique : l'effondrement du modèle.
Si de nouveaux réseaux neuronaux sont entraînés sur des données contenant une forte proportion de contenu IA, le système commence à exploiter ses propres réponses moyennées. Cela réduit la variabilité, dégrade la qualité et risque de conduire les modèles d'apprentissage automatique à apprendre non pas des humains, mais de l'« écho synthétique » de leurs prédécesseurs.
Des experts, en collaboration avec Internet Archive, prévoient de transformer ces recherches en un système de surveillance continue de la part de contenu relatif à l'IA sur Internet.
Rappelons qu'en avril, Sam Altman a énoncé les cinq principes d'OpenAI pour parvenir au « bien commun de l'IA ».