

La startup chinoise DeepSeek, spécialisée en intelligence artificielle, a dévoilé un aperçu de sa nouvelle gamme de modèles de langage. Son modèle phare, le V4-Pro, a surpassé Claude Opus 4.6 et GPT-5.4 pour devenir le meilleur système ouvert.
🚀 La préversion de DeepSeek-V4 est officiellement lancée et en open source ! Bienvenue dans l'ère d'un million de contextes accessibles par jeton.
🔹 DeepSeek-V4-Pro : 1 600 milliards de paramètres au total / 49 milliards de paramètres actifs. Des performances équivalentes à celles des meilleurs modèles en boucle fermée au monde.
🔹 DeepSeek-V4-Flash : 284 milliards de paramètres au total / 13 milliards de paramètres actifs… pic.twitter.com/n1AgwMIymu– DeepSeek (@deepseek_ai) 24 avril 2026
Architecture et échelle
La version V4-Pro comporte environ 1 600 milliards de paramètres, mais seulement 49 milliards sont activés à chaque étape. Dans la seconde version, V4-Flash, le nombre total de paramètres atteint 284 milliards, dont 13 milliards sont activés.
Les deux modèles reposent sur une architecture de type « Mixte d’experts » (MoE) : seule la partie pertinente des sous-réseaux est activée lors du traitement de chaque jeton. Cette approche est moins coûteuse que les architectures entièrement denses, sans pour autant leur être inférieure en termes de performances.
L'entraînement initial a été réalisé sur un corpus de plus de 32 000 milliards de jetons. Les développeurs ont ensuite entraîné les modèles de manière incrémentale, en allouant des blocs distincts au codage, aux mathématiques, à la logique et au suivi des instructions. La version finale combine ces compétences par distillation.
Le contexte long est devenu moins cher
La principale différence de la version 4 résidait dans l'optimisation du traitement des longues séquences. La fenêtre de contexte d'un million de jetons est également disponible dans d'autres modèles, mais son utilisation est généralement associée à un coût et une latence élevés.
DeepSeek a indiqué que la nouvelle version réduit considérablement la consommation de ressources pour ces opérations. Par rapport à la version 3.2, la V4-Pro nécessite environ 27 % de calculs en moins et 10 % de mémoire cache KV en moins avec un contexte maximal. Pour la V4-Flash, ces chiffres sont respectivement d'environ 10 % et 7 %.
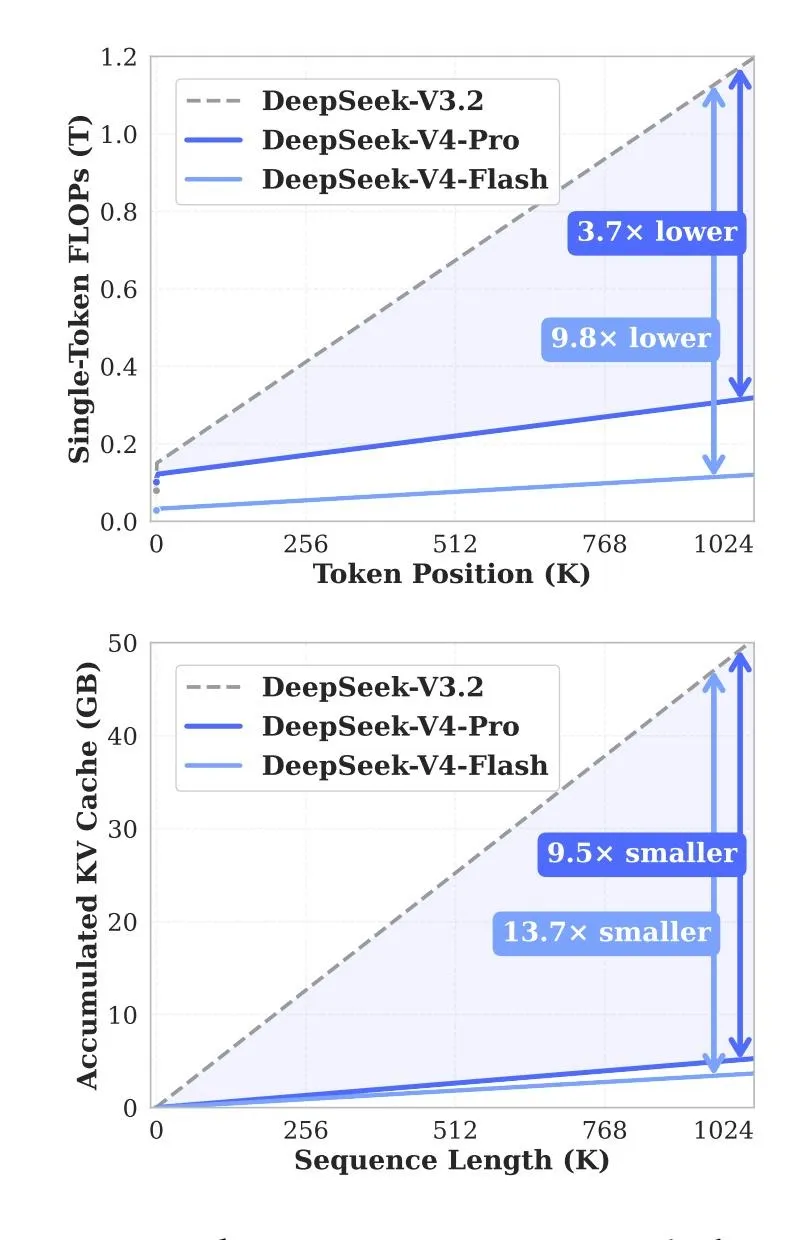
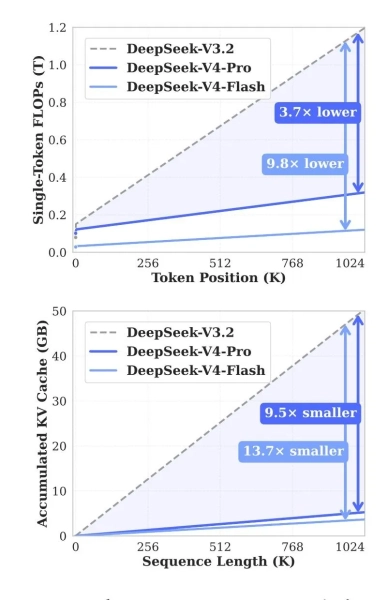
Source : Hugging Face.
L'équipe a obtenu ce résultat grâce à une architecture d'attention hybride : deux mécanismes compressent les données et réduisent la charge de travail lors du traitement de textes longs. Elle utilise également des hyperliens spécifiques pour assurer la stabilité et l'optimiseur Muon pour accélérer l'apprentissage.
Modes de raisonnement et capacités d'agentivité
DeepSeek V4 prend en charge trois modes de raisonnement :
- Réponses rapides et superficielles à des questions simples, sans analyse approfondie.
- Penser en profondeur — une analyse approfondie pour les tâches et la planification complexes.
- Think Max — mode maximum : le modèle parcourt chaque étape et vérifie toutes les options.
Dans les tâches d'agent, le mode Max préserve désormais la chaîne des étapes intermédiaires au sein d'une même tâche. Dans la version précédente, une partie de ce contexte était perdue lors des interactions avec l'utilisateur.
Résultats des tests
Selon DeepSeek, la version phare affiche des résultats comparables aux systèmes de pointe dans plusieurs domaines :
- Dans les tâches de programmation sur Codeforces, le modèle a atteint une note de 3206 — la 23e place parmi les programmeurs actifs dans le monde, à égalité avec GPT-5.4 ;
- En mathématiques, elle a obtenu un score de 95,2 au HMMT 2026 et de 89,8 à l'IMOAnswerBench, devant la plupart des concurrents ;
- en connaissances SimpleQA Verified — 57,9 (Opus 4.6 — 46,2, mais Gemini 3.1 Pro — 75,6).
- En matière de raisonnement, les modèles ne sont en retard que de trois à six mois sur GPT-5.4 et Gemini 3.1 Pro ;
- Dans le test interne DeepSeek, couvrant le développement, le débogage et la refactorisation, le modèle a atteint 67 % — entre Sonnet 4.5 (47 %) et Opus 4.5 (70 %) ;
- Dans les scénarios d'agents et les tâches de développement, V4-Pro-Max a démontré 80,6 % sur SWE Verified et 67,9 % sur Terminal Bench.
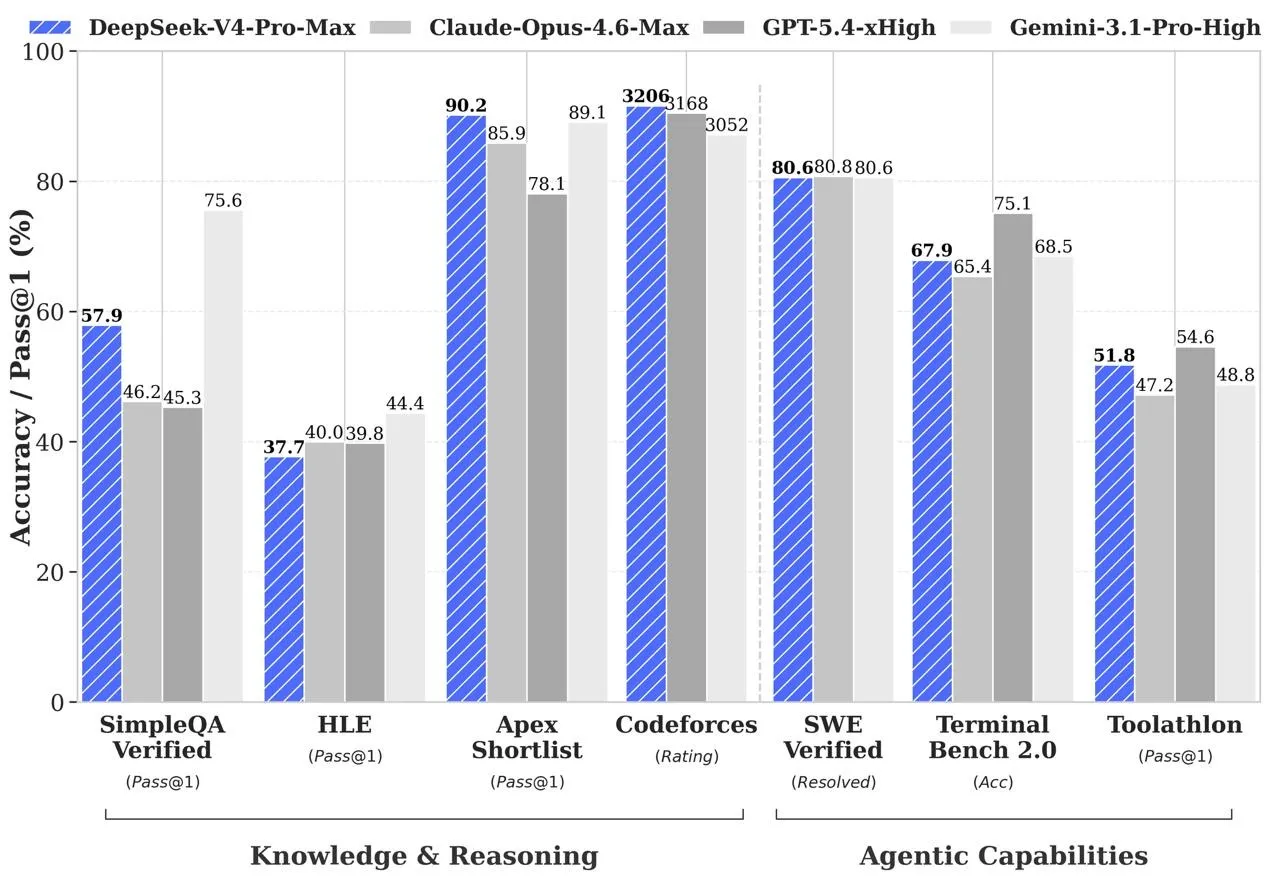
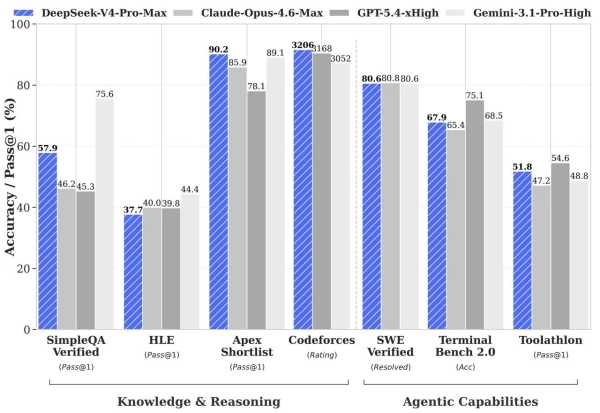
Source : Hugging Face.
V4 a été spécialement entraîné sur des scénarios réels : analyse de données, rapports, édition de documents et recherche sur Internet avec une utilisation itérative des outils.
Pour évaluer la pertinence du modèle dans un contexte de développement réel, la start-up a mené des tests internes sur les tâches de ses ingénieurs. Sur 85 développeurs et chercheurs interrogés, 52 % se sont déclarés prêts à utiliser V4-Pro comme modèle principal de programmation, et 39 % ont indiqué être enclins à faire ce choix.
Pour rappel, OpenAI a publié GPT-5.5 le 23 avril. Ce modèle est présenté comme « un nouveau niveau d'intelligence pour le travail dans le monde réel et la gestion des agents ».